By Shreyas Kaundinya
What is MVCC?
Imagine a scenario, you have just deployed an application that allows multiple employees from an organization do CRUD operations on TODO list, a simplified JIRA board. You have your frontend on the web where the users login and perform their operations. There's a HTTP server taking requests and all the data is stored in a DB.
Now for examples sake, lets say that the DB only allows only single operation at a time.
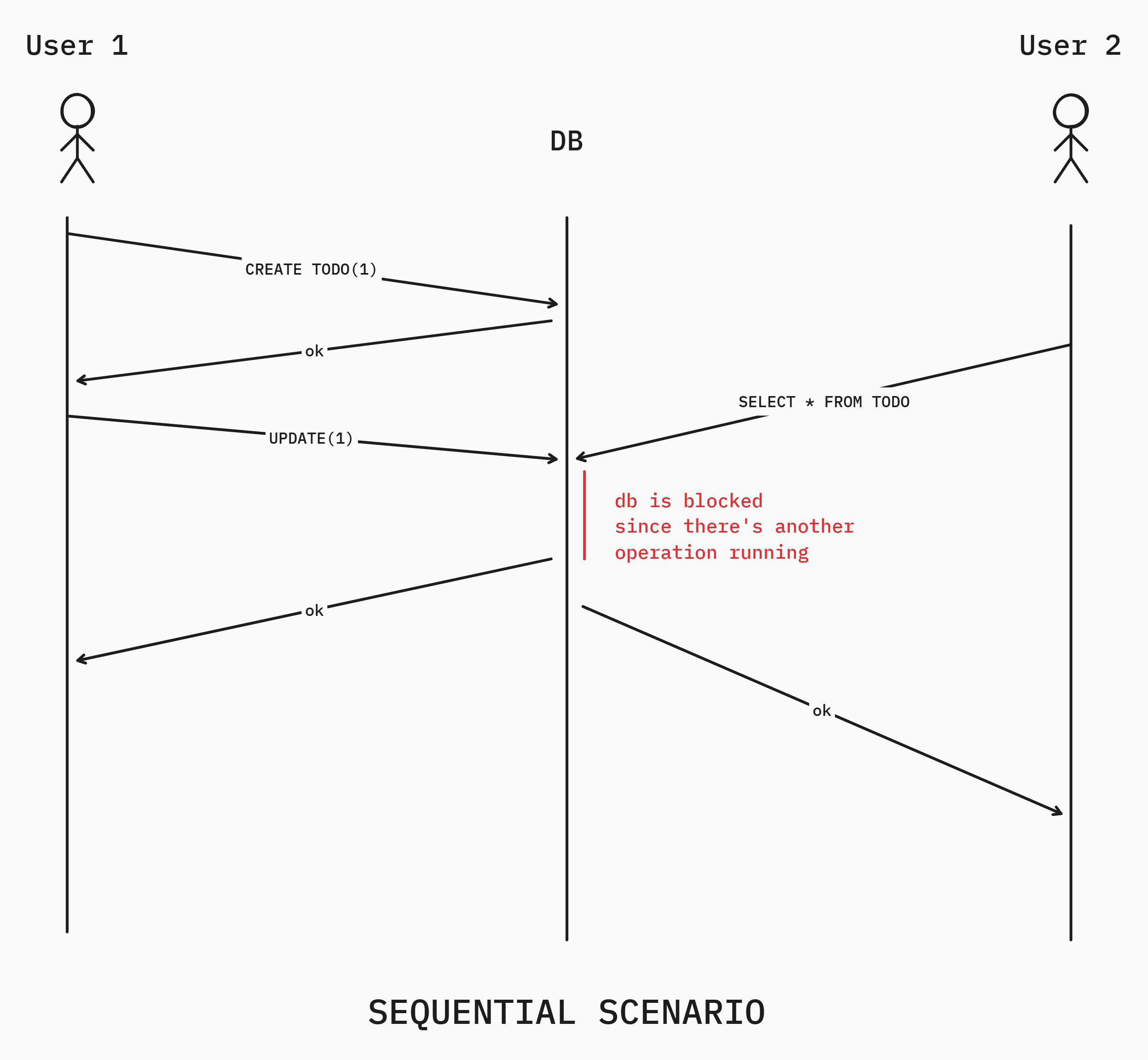
Fig(1) Sequential execution
You can see how each operation runs sequentially in the DB. Each operation waits for the previous one to finish to then execute itself.
This does seem inefficient doesn't it.
Now lets say we replace this sequential DB with PostgreSQL, with the power of MVCC or Multi Version Concurrency Control, we can run things concurrently.
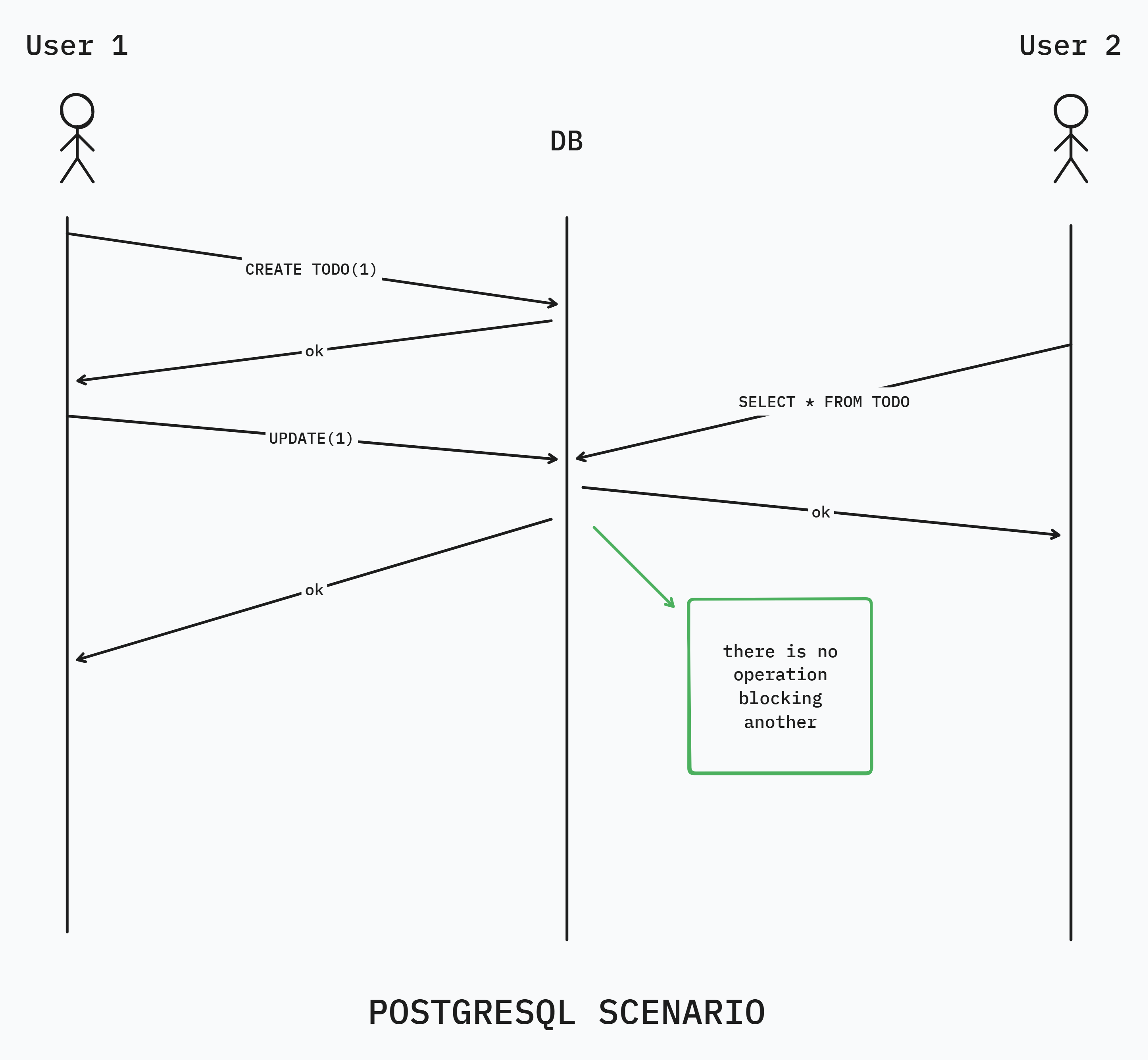
Fig(2) Concurrent execution
The essence of having MVCC is to provide the application using the DB to not choke a read because of a write and a write because of a read. To do this, MVCC systems never overwrite existing data, so that concurrent transactions can continue to read them if they need to. New versions of data are created. Everyone running a transaction gets to see some data and is not blocked by other transactions.
Of course, MVCC is an age old technology dating back to 1979 where it was first seen in a dissertation. It was first implemented in InterBase. In many different flavors we now see it in modern databases.
Glossary
Quick intervention to checkout the system columns and some definitions.
tuple: we will use row and tuple interchangeablydead tuple: a tuple that has been marked as deleted by a transactiontransaction: a sequence of operations that are executed atomically and are either committed or rolled backVACUUMis a garbage collection process that helps to clean up dead tuples and reclaim the space used by them. (There is more to it than that, we shall discuss in later sections).autovacuumis a background process that runs VACUUM on different tables to free up space.page: a block of memory that contains some headers and tuples.
transaction ID: it's a 32 bit integer that is assigned to every transaction that gets created. (Yes there are around a billion possible numbers in 32 bits and it does wrap around in case it's exhausted)xmin: it is the transaction ID that inserted the particular row versionxmax: it is the transaction ID that deleted the particular row versionctid: the location of the row in the table. It has two numbers(block number, position/offset within block).ctidcan change when the row is updated or a VACUUM FULL has run.
pageinspect extension provides us with some functions to inspect the physical pages of the table.
heap_page_itemsfunction is used to get the items (tuples) from a heap page.lp: line pointer; this is the offset of the tuple in the page.t_xmin: the transaction ID that inserted the tuple (corresponds to thexmincolumn in the system columns).t_xmax: the transaction ID that deleted the tuple (corresponds to thexmaxcolumn in the system columns).t_ctid: the location of the tuple in the table (corresponds to thectidcolumn in the system columns).t_infomask: flags for additional metadata about the tuplet_infomask2: flags for additional metadata about the tuple- it provides other information which we will not be using in this post.
Here's a reference to table row layout : Documentation
heap_tuple_infomask_flags: function that gives us the verbose representation of the flags.
NOTE: Transaction by default has read committed isolation level. We will deep dive into isolation and the levels in another post but for now, just know that it's the default isolation level. Read committed allows each transaction to only see the data that has been committed to the database.
Let's dig a bit into PostgreSQL's implementation.
MVCC : In Action
I suggest that you follow along with your instance of PostgreSQL as its super fun that way. Here's a guide to download it https://www.postgresql.org/download/.
For this example, I'll be using PostgreSQL 16.1
1select version();
2
3>>> PostgreSQL 16.1, compiled by Visual C++ build 1937, 64-bit
Lets create a database to isolate the example
1CREATE DATABASE mvccinaction;
Let's install an extension called pageinspect. This will allow us to inspect the physical pages of the table.
1CREATE EXTENSION pageinspect;
Now lets create a table called todo from the example above
1CREATE TABLE todo (
2 id SERIAL PRIMARY KEY,
3 name text not NULL,
4 description text,
5 status text DEFAULT 'PENDING'
6);
Let's start by disabling autovacuum
1ALTER TABLE public.todo SET (autovacuum_enabled = off);
Table is now all set, lets start a transaction and insert a couple of rows.
1start transaction;
2
3SELECT txid_current();
Should see something like this :
1txid_current|
2------------+
3 550937|
If at any point you get some error, run the following and start a new transaction.
1rollback;
1INSERT INTO todo (name, description, status)
2VALUES
3 ('Buy groceries', 'Milk, eggs, bread, and fruits', 'PENDING'),
4 ('Finish project report', 'Complete the draft and send to manager', 'PENDING');
Select the values to see that everything is set. It will also set the baseline information.
1select ctid, xmin, xmax, * from todo;
2
3ctid |xmin |xmax|id|name |description |status |
4-----+------+----+--+---------------------+--------------------------------------+-------+
5(0,1)|550937|0 | 1|Buy groceries |Milk, eggs, bread, and fruits |PENDING|
6(0,2)|550937|0 | 2|Finish project report|Complete the draft and send to manager|PENDING|
xminis the same as the current inserting transaction.ctidshows that the rows exist inside block 0 and are at offset 1, 2 respectively.xmaxis 0 since it hasn't been deleted yet.
1commit;
Inspecting the page :
1SELECT lp, t_xmin, t_xmax, t_ctid, heap_tuple_infomask_flags(t_infomask, t_infomask2)
2FROM heap_page_items(get_raw_page('public.todo', 0));
3
4lp|t_xmin|t_xmax|t_ctid|heap_tuple_infomask_flags |
5--+------+------+------+-------------------------------------------+
6 1|550937|0 |(0,1) |("{HEAP_HASVARWIDTH,HEAP_XMAX_INVALID}",{})|
7 2|550937|0 |(0,2) |("{HEAP_HASVARWIDTH,HEAP_XMAX_INVALID}",{})|
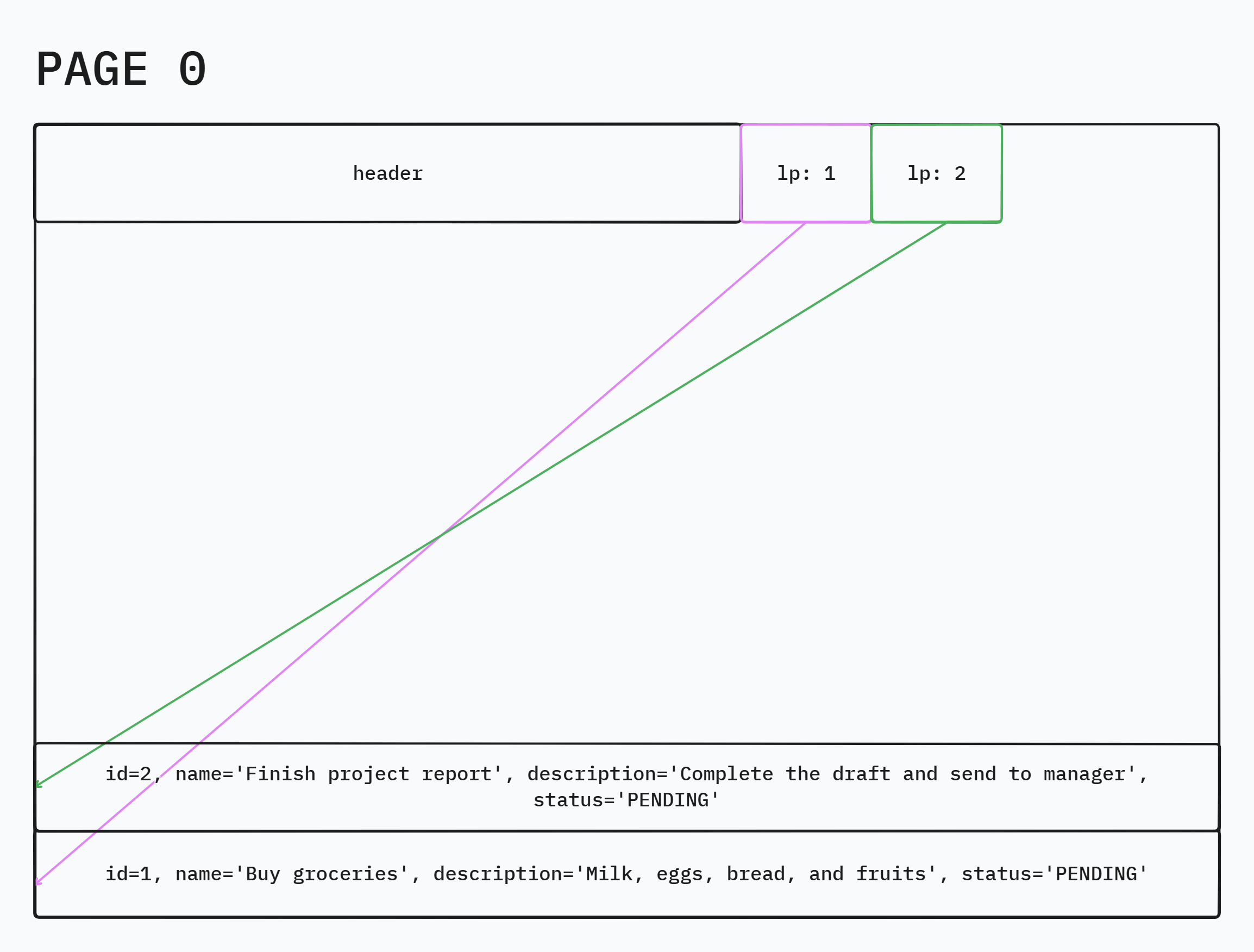
Fig(3) How the page looks like after the INSERTs
Let's now commit this transaction.
UPDATEs
Let's start a new transaction.
1start transaction;
2
3SELECT txid_current();
1txid_current|
2------------+
3 550938|
Let's update the status of the first row to COMPLETED.
1UPDATE todo SET status = 'COMPLETED' WHERE id = 1;
Now, observe the changes in the system columns.
1select ctid, xmin, xmax, * from todo;
2
3ctid |xmin |xmax|id|name |description |status |
4-----+------+----+--+---------------------+--------------------------------------+---------+
5(0,2)|550937|0 | 2|Finish project report|Complete the draft and send to manager|PENDING |
6(0,3)|550938|0 | 1|Buy groceries |Milk, eggs, bread, and fruits |COMPLETED|
- A new row has been created with the new transaction ID for the
id = 1row. xmin: has now changed from550937to550938since it's the new transaction ID.xmax: is still 0 since it hasn't been deleted yet.ctid: has changed from(0,1)to(0,3)since it's the new row, it takes a new offset in the same block.
Where has the old row gone?
It still exists, but our current transaction cannot see it. It's been marked as deleted.
Let's now open another terminal where we start a new transaction and check the values from the table.
1-- Terminal 2
2select ctid, xmin, xmax, * from todo;
3
4ctid |xmin |xmax |id|name |description |status |
5-----+------+------+--+---------------------+--------------------------------------+-------+
6(0,1)|550937|550938| 1|Buy groceries |Milk, eggs, bread, and fruits |PENDING|
7(0,2)|550937|0 | 2|Finish project report|Complete the draft and send to manager|PENDING|
- We now see the old row with
id = 1with thePENDINGstatus. xmaxis now550938since it's been marked as deleted by the concurrent transaction.
Let's now commit the second transaction that ran the update.
1-- Terminal 1
2commit;
Since, the transactions by default have read committed isolation level, the changes are visible to the current transaction.
1-- Terminal 2
2select ctid, xmin, xmax, * from todo;
3
4ctid |xmin |xmax|id|name |description |status |
5-----+------+----+--+---------------------+--------------------------------------+---------+
6(0,2)|550937|0 | 2|Finish project report|Complete the draft and send to manager|PENDING |
7(0,3)|550938|0 | 1|Buy groceries |Milk, eggs, bread, and fruits |COMPLETED|
Heap only Tuples (HOT)
HOT deserves it's own blog post. But that's for another time.
Updates in PostgreSQL are inherently bad due to the design of MVCC. They require new versions for each update and, the new version is a full copy of the tuple along with the new change. Theoretically this will in turn require deletion of old versions and updation of indices.
(cue dramatic music)
HOT comes into play.
Optimizations:
Index
Updates no longer require a new entry in indices unless the update involves an field that is part of the index. This saves disk I/0 and CPU cycles. HOT CHAIN : linking of the original row is provided to the newest version, any version in between which are not used by any concurrent transaction can be vacuumed.
New Tuples
New tuples are placed in the same disk page as the old tuple and a pointer points the old tuple to the new one, provided there's space on the page.
fillfactor : parameter that can be set to make sure a page doesn't fill beyond this percentage, making the rest available for HOT.
Going back to the UPDATEs section. Let's check the the statistics for the table in pg_stat_user_tables.
1select n_tup_hot_upd, n_tup_newpage_upd from pg_stat_user_tables;
n_tup_hot_upd: number of tuples updated using HOT.n_tup_newpage_upd: number of tuples updates that resulted in the tuple being moved to a new page.
1n_tup_hot_upd|n_tup_newpage_upd|
2-------------+-----------------+
3 1| 0|
We see that 1 tuple was updated using HOT. This co-relates to the fact that our ctid has changed from (0,1) to (0,3) for the id = 1 row, meaning that it didn't move into a new block.
1SELECT lp, t_xmin, t_xmax, t_ctid, heap_tuple_infomask_flags(t_infomask, t_infomask2)
2FROM heap_page_items(get_raw_page('public.todo', 0));
3
4lp|t_xmin|t_xmax|t_ctid|heap_tuple_infomask_flags |
5--+------+------+------+------------------------------------------------------------------------+
6 1|550937|550938|(0,3) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED}",{}) |
7 2|550937|0 |(0,2) |("{HEAP_HASVARWIDTH,HEAP_XMAX_INVALID}",{}) |
8 3|550938|0 |(0,3) |("{HEAP_HASVARWIDTH,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE}",{})|
- We can see that the original tuple with
id = 1has a new flagHEAP_HOT_UPDATEDset. - The new tuple with
id = 1has a new flagHEAP_UPDATEDandHEAP_ONLY_TUPLEset.

Fig(4) How the page looks like after the UPDATE
DELETEs
Let's start a new transaction.
1-- Terminal 1
2start transaction;
3
4SELECT txid_current();
5
6txid_current|
7------------+
8 550940|
Let's delete a row.
1-- Terminal 1
2DELETE FROM todo WHERE id = 1;
Our current transaction only sees one row with id = 2
1-- Terminal 1
2select ctid, xmin, xmax, * from todo;
3
4ctid |xmin |xmax|id|name |description |status |
5-----+------+----+--+---------------------+--------------------------------------+-------+
6(0,2)|550937|0 | 2|Finish project report|Complete the draft and send to manager|PENDING|
Before we commit, let's open another transaction in the second terminal and check the values from the table.
1-- Terminal 2
2select ctid, xmin, xmax, * from todo;
3
4ctid |xmin |xmax |id|name |description |status |
5-----+------+------+--+---------------------+--------------------------------------+---------+
6(0,2)|550937|0 | 2|Finish project report|Complete the draft and send to manager|PENDING |
7(0,3)|550938|550940| 1|Buy groceries |Milk, eggs, bread, and fruits |COMPLETED|
- We now see the old row with
id = 1with theCOMPLETEDstatus. xmaxis now550940since it's been marked as deleted by the concurrent transaction.
Let's commit the transaction that ran the delete.
1-- Terminal 1
2commit;
1-- Terminal 1
2SELECT lp, t_xmin, t_xmax, t_ctid, heap_tuple_infomask_flags(t_infomask, t_infomask2)
3FROM heap_page_items(get_raw_page('public.todo', 0));
4
5lp|t_xmin|t_xmax|t_ctid|heap_tuple_infomask_flags |
6--+------+------+------+--------------------------------------------------------------------------------------------+
7 1|550937|550938|(0,3) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_HOT_UPDATED}",{}) |
8 2|550937|0 |(0,2) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID}",{}) |
9 3|550938|550940|(0,3) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_UPDATED,HEAP_KEYS_UPDATED,HEAP_ONLY_TUPLE}",{})|
- We can see that the original tuple with
id = 1has a new flagHEAP_XMAX_COMMITTEDset.

Fig(5) How the page looks like after the DELETE
Vacuum
We previously discussed that a DELETE operation just marks the tuple as deleted, and an UPDATE operation creates a new tuple with the new values and making the old tuple obsolete. This could potentially bloat up the tables and take up a ton of disk space.
Vacuum is the process of cleaning and reclaiming the space used by the dead/obsolete tuples. autovacuum is the background process that runs VACUUM on different tables/relations to free up space.
Let's check the statistics for the table in pg_stat_user_tables.
1-- Terminal 1
2select n_tup_del, n_tup_upd, n_live_tup, n_dead_tup from pg_stat_user_tables;
3
4n_tup_del|n_tup_upd|n_live_tup|n_dead_tup|
5---------+---------+----------+----------+
6 1| 1| 1| 2|
n_tup_del: number of tuples deleted = 1n_tup_upd: number of tuples updated = 1n_live_tup: number of live tuples = 1n_dead_tup: number of dead tuples = 2
The dead tuples still exist the physical disk but are not visible to the current transaction as xmax is not 0. These are the tuples that are waiting to be VACUUMMED.
1-- Terminal 1
2SELECT lp, t_xmin, t_xmax, t_ctid, heap_tuple_infomask_flags(t_infomask, t_infomask2)
3FROM heap_page_items(get_raw_page('public.todo', 0));
4
5lp|t_xmin|t_xmax|t_ctid|heap_tuple_infomask_flags |
6--+------+------+------+--------------------------------------------------------------------------------------------+
7 1|550937|550938|(0,3) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_HOT_UPDATED}",{}) | -- ---> original tuple with id = 1
8 2|550937|0 |(0,2) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID}",{}) | -- ---> original tuple with id = 2
9 3|550938|550940|(0,3) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_UPDATED,HEAP_KEYS_UPDATED,HEAP_ONLY_TUPLE}",{})| -- ---> updated tuple with id = 1
Let's now run vacuum on table todo.
1-- Terminal 1
2VACUUM FULL todo;
If you find that the vacuum is stuck, run
rollbackon terminal 2 asVACUUM FULLrequires an exclusive lock on the entire table.
Let's run ANALYZE to update the statistics.
1ANALYZE todo;
Let's now check the statistics for the table in pg_stat_user_tables.
1-- Terminal 1
2select n_tup_del, n_tup_upd, n_live_tup, n_dead_tup from pg_stat_user_tables
3where relname = 'todo';
4
5n_tup_del|n_tup_upd|n_live_tup|n_dead_tup|
6---------+---------+----------+----------+
7 1| 1| 1| 0|
8
9
10SELECT lp, t_xmin, t_xmax, t_ctid, heap_tuple_infomask_flags(t_infomask, t_infomask2)
11FROM heap_page_items(get_raw_page('public.todo', 0));
12
13lp|t_xmin|t_xmax|t_ctid|heap_tuple_infomask_flags |
14--+------+------+------+-------------------------------------------------------------------------------------------------+
15 1|550937|0 |(0,1) |("{HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID}",{HEAP_XMIN_FROZEN})|
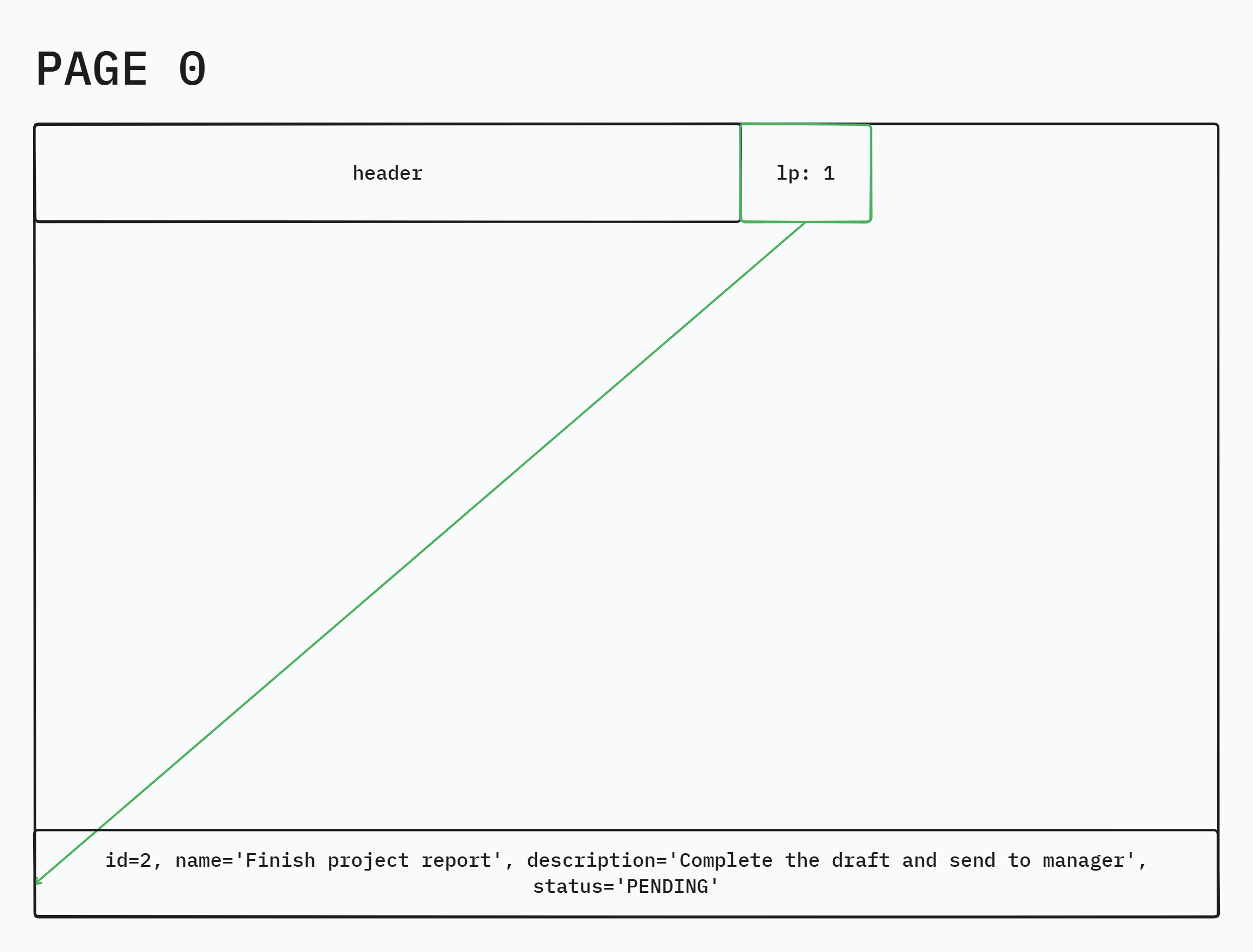
Fig(6) How the page looks like after the VACUUM FULL
We see that the dead tuples have been vacuumed.
Cleanup
1drop database mvccinaction;
Final Notes
MVCC is a powerful feature that allows for concurrent operations on the same data. It's a key component of PostgreSQL's ACID compliance. It has its pitfalls as we have seen in this post.
Thank you for reading.
Do share your thoughts and feedback, find me :
References
- The part of PostgreSQL we hate the most by Andy Pavlo
- The Internals Of PostgreSQL - 7.1. Heap Only Tuple (HOT)
- Postgres Performance Boost: HOT Updates and Fill Factor by Elizabeth Christensen
- Internals of MVCC in Postgres: Hidden costs of updates vs inserts by Rohan Reddy
- PostgreSQL Internals in Action
- PostgreSQL Documentation - System Columns
- Postgres, MVCC, and you or, Why COUNT(*) is slow (David Wolever)
Post Changelog
- 2025-10-15 : Initial version
- 2025-10-16 : Added more information on system columns and flags
- 2025-10-20 : Added images, refactored information